

庖丁科技打造行业领先的债券询报价大模型

在“人工智能+”深入赋能金融行业、助力新质生产力发展的战略背景下,庖丁科技与头部券商深度合作,研发打造了债券询报价大模型,并正式投入实战。
该系统通过深度赋能债券二级市场交易场景,扫除了自动化交易上的重要技术障碍。
一、现实挑战:债券交易询价三大困境
一、现实挑战:债券交易询价三大困境
近几个月,国内银行间债券市场现券成交日均成交约1.5万亿元。
尽管交易量巨大,债券二级市场绝大多数交易仍通过场外(OTC)询价完成,即时通讯工具成为了交易信息流转的核心载体。
这些散落在各类聊天窗口中的询价与报价信息,绝大多数以非结构化的自然语言文本形式存在,其中存在大量行业术语、交易“黑话”及交易员个性化的口语表达。
在此情形下,整个行业在快速找到交易对手方都面临着三大现实困境:
1. 信息碎片化导致决策响应滞后
关键信息散落在众多窗口中,难以实时聚合与可视化。
交易员在多任务频繁切换、手工核对中,极易陷入“看不清市场、跟不上节奏”的被动困局。
2.语言表达多变导致规则覆盖不足
同一债券或资金需求存在千百种自然语言变体。
传统关键词与模板的解析方式难以适应复杂的口语习惯,导致大量有效询价无法被准确识别,错失交易机会。
3.高压决策环境推高操作风险
信用债等流动性相对不足的品种,其成交价格高度依赖交易员的即时判断。
债市行情波动剧烈时,交易员必须在海量非标准化信息中快速甄别有效报价,不仅面临极大的心理压力,也容易因人工误判引发定价偏差与声誉风险。
上述瓶颈不仅大幅加重了交易员的工作负荷,也推高了操作成本、压缩盈利空间,成为制约机构交易效率与核心竞争力的关键障碍。
债券交易询价三大困境
二、核心难点询报价信息,金融语义“深水区”
二、核心难点询报价信息,金融语义“深水区”
面对上述现实困境,引入 AI 解析报价已成为金融机构数字化转型的必然选择。
然而,要在高频变动的交易环境中实现精准的询报价解析,有两个难点必须解决:
1. 行业术语高度复杂,解析容错率“零容忍”
询报价信息具有极高的信息密度。
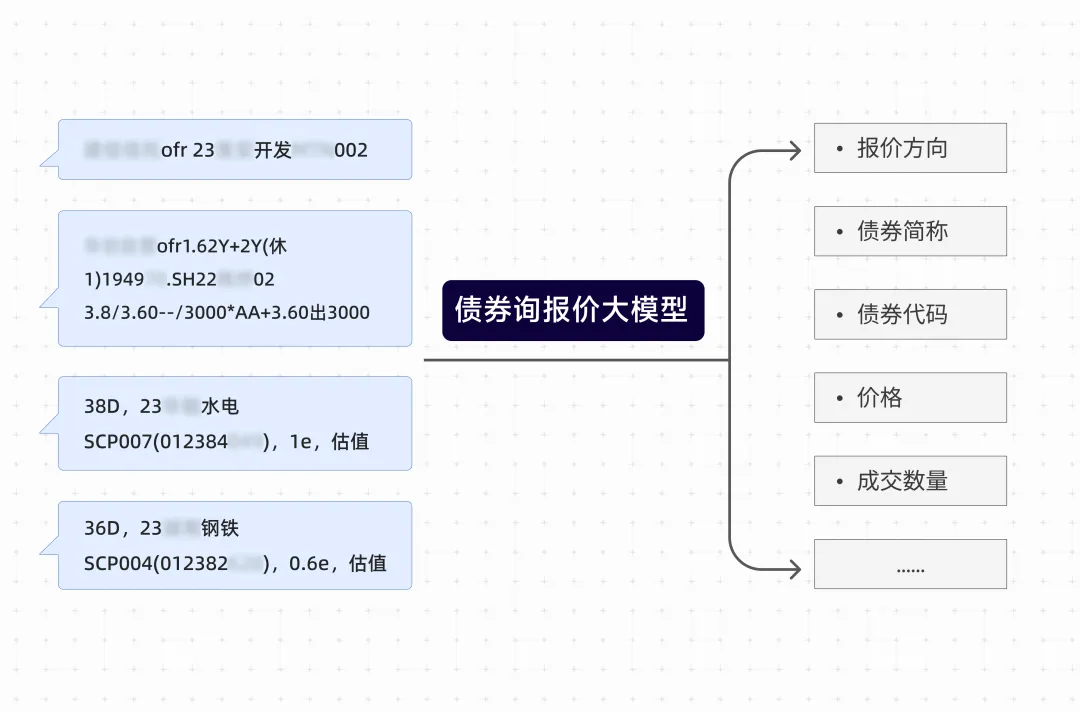
一条短短的文本通常涵盖了报价方向、债券简称、代码、价格、成交数量、清算速度及有效时间等多个关键变量。
在真实的询报价语境下,信息往往以极端紧凑的形式呈现。
例如,图中为交易群聊中一条真实的交易信息:

以其中一条报价信息为例:
“××自营ofr1.62Y+2Y(休1)1949××.SH 22×× 02 3.8/3.60--/3000*AA+3.60出3000”*
能够看到,短短一串字符中,就包含了:
“ofr”报价方向、“1949××.SH”债券代码、“22××”债券简称、“3.8”Bid价格、“3.60”Ofr价格、“*”交易是否请示、“3000”Ofr数量等多个维度的交易要素。
这种高度复杂的专业表达方式,对解析系统的细颗粒度识别能力提出了苛刻的要求。
基于正则表达式的传统方案在面对真实、灵活的表述时,准确率往往不足 70%,极易造成关键字段漏读。
而通用的预训练模型(例如ChatGPT等)则缺少金融垂类的专业知识,导致无法准确处理高度复杂的专业信息,导致后续识别交易指令失效。
2.行业行话持续演变,面对新表述要“跟得上”
此外,债市交易用语也并非静态不变,而是随着市场环境不断动态演化。
在复杂的交易语境下,同个字段的含义也会根据上下文不同而发生剧烈变化。
传统模型一旦面对训练集中少见的表达方式,解析表现便会大幅下降。
以债券交易中常见的“+1”识别为例:
在常规训练场景下,模型通过学习“估值 +1 ofr 1.61Y 债券1” 这类表达,识别出紧跟在估值之后的“+1”代表在估值基础上加点,即指向「价格」。
而在实际部署后的真实对话中,可能会出现如“+1 3.31 1.85Y 债券2”这种在训练过程中未出现的表达。
如果 AI 仅仅依赖简单的位置特征或字面匹配,会机械地将句首的“+1”再次识别为「价格」,从而导致整条指令解析错误。
实际上,由于该文本中已经出现了明确的代表「价格」的数字“3.31”,根据交易逻辑,本句中的“+1”其实指「清算速度」(即 T+1 )。

传统模型存在解析局限性
因此,模型需要具备“快速适应训练中未出现过的表述”这一能力,以持续跟进行业的演进。
三、技术创新:
基于大模型的智能询报价解析方案
三、技术创新:
基于大模型的智能询报价解析方案
针对上述痛点,庖丁科技联合头部券商打造了债券询报价大模型。
该系统基于庖丁科技深厚的金融自然语言处理(NLP)积淀,针对金融交易的高频、高准度要求,构建起一套完整、可落地的工程化框架,训练了适合此场景的垂域大模型:询报价解析大模型,解决了上述难题。
在完整系统评测中,该大模型在询报价解析任务上准确率高达约96%,显著优于传统方案与未微调模型。
结合vLLM推理框架和推测解码技术,在低资源条件下实现高精度、低延迟推理。
在面对多样化、长尾场景和新表述时,只需少量标注就能够快速适应新表达、新话术,模型能够持续进化。
债券询报价大模型智能解析方案
四、应用成效:从“效率瓶颈”到“价值创造”
四、应用成效:从“效率瓶颈”到“价值创造”
截至目前,该债券询报价大模型已深度融入头部券商真实、高频的固收交易场景,成为驱动业务效率提升的关键引擎。
该系统直击债券询价过程中最根本的“信息决策”断点,通过智能解析实现从“非结构化沟通”到“结构化执行”的跨越,完成了从“人工滞后处理”到“系统实时就绪”的流程重构,助力公司在“快市场”中建立起持续、敏捷的响应能力。
1.交易效率提升
针对债券市场“快市场、慢流程”的长期矛盾,该债券询报价大模型的自动解析替代了过去依赖人工逐条识别、反复确认的原始模式,可以承受高峰时段每小时数千笔非标准化询价的解析需求。
解决了因交易“行话”多、表达灵活导致的传统规则模型覆盖不足问题,极大减轻了交易员在信息预处理环节的认知负荷与操作成本。
2.业绩规模化增长
该债券询报价大模型通过实现“信息不遗漏、响应不延迟”,显著提升了有效交易机会的触达与转化效率。
在生产环境中的A/B对照测试结果表明:借助大模型辅助处理询报价,使得交易量实现了数倍增长。
这一提升不仅直接带来了可观的业务增长,也显著增强了公司在关键交易时点的市场竞争力与定价话语权。
3.风险管理范式革新
为进一步保障执行安全与合规需求,该询报价大模型系统内嵌黑白名单、价格校验、额度实时监控等多重风控机制,在提升响应效率的同时,有效抑制“模型幻觉”与操作风险。
由此,该询报价大模型以智能解析为起点,扫除了自动化交易上的重要技术障碍,更在高速运转的市场中构建出稳定、可靠、可持续的智能交易闭环。
五、未来展望
五、未来展望
本次庖丁科技与头部券商合作研发落地的债券询报价大模型,为债券询价这一重要业务场景,贡献了可复制、可量化的智能方案。
与此同时,该系统也为固定收益类产品交易提供了深度支持能力,并支持以轻量化、模块化的方式集成至机构现有的交易系统中。
未来,庖丁科技将继续秉持“场景驱动、价值创造”的初心,深度链接更多金融行业领先机构,加快债券询报价大模型技术体系在多资产、衍生品、国际化等更多场景的复制推广,以AI大模型赋能核心业务,为金融科技创新和业务高质量发展不断注入新的动能。







点击“阅读原文”联系我们
了解关于债券询报价大模型更多信息







