ChatDOC 以及其他 AI 工具是我们高效阅读文档的绝佳助手,但考虑到生成式 AI 模型的特性,不同的问题表达方式可能导致截然不同的回答。因此,掌握准确的提问技巧显得尤为关键。
如何召唤出自己想要的信息?请牢记这个口诀:
少量多次,问题导向。
客观具体,不抠细节。
问题越聚焦,回答效果就越好。
这是因为,ChatDOC 需要从海量文档中检索出与提问最匹配的几段文字作为依据来回答问题。
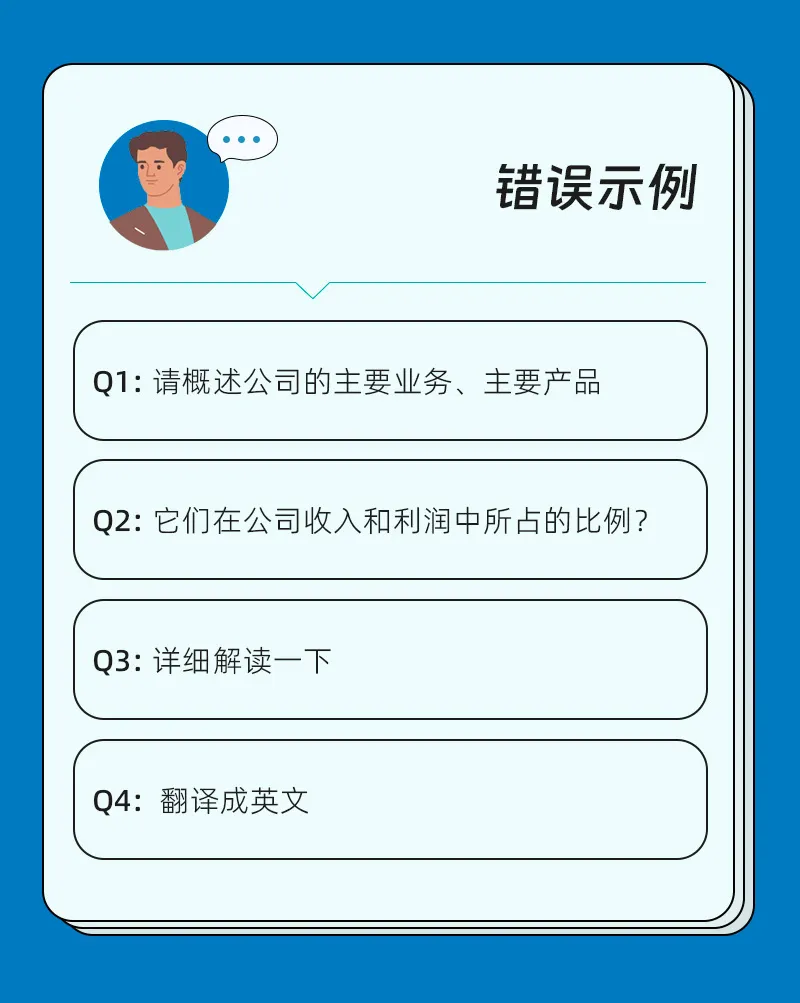
如果一次性提出很多问题,ChatDOC 很难对每个问题都匹配到足够相关和充足的文档内容,也就无法生成高质量的回答了。
大模型一次只能处理有限的词数。例如 GPT -3.5 目前的限制是 4096 个 token,大致相当于 3000 多个单词。这就决定了,每一次的问题、检索的文档片段以及得到的答案,加起来不能超过 3000 个单词。
主对话框里,每个问题之间都独立分开的, ChatDOC 不会自动记住之前的问题和回答。所以提出每个新问题时,需要输入完整的问题内容。
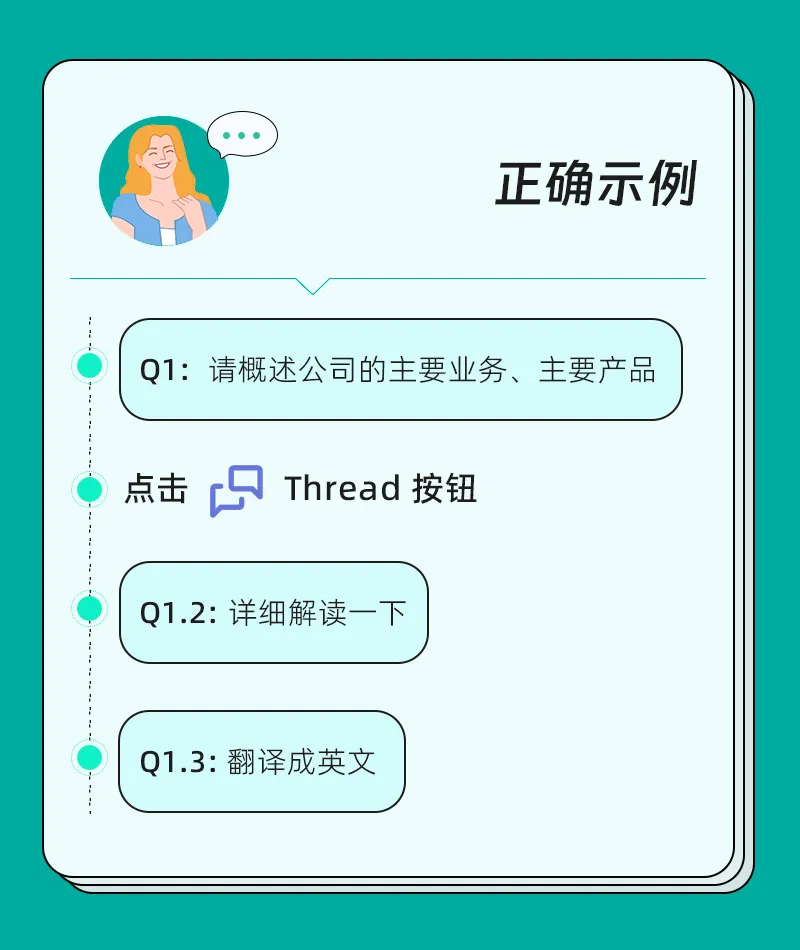
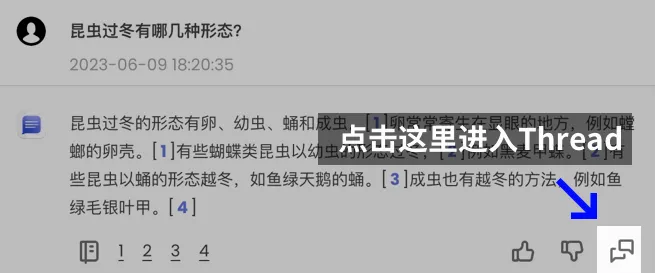
若想让 ChatDOC 记住当前对话的上下文,可以进入 Thread 进行追问。此时你还可以选择让它严格按照原文回答,或在这个话题下自由发挥。
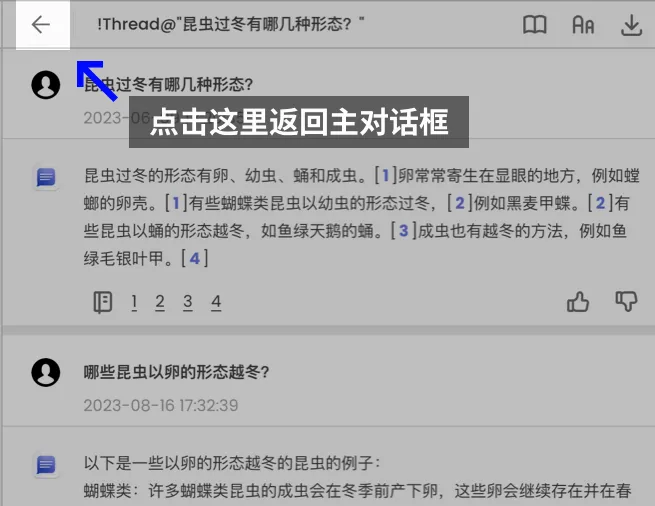
追问完成后,记得回到主对话框,再开启下一个话题的询问。
如果第一轮问答就让 ChatDOC 自由发挥,那么它生成的内容就无法溯源找到原文出处,跟 ChatGPT 就没有区别了:AI 无法知晓信息来自哪里,有可能是它自己臆造的,与文档没有关系。
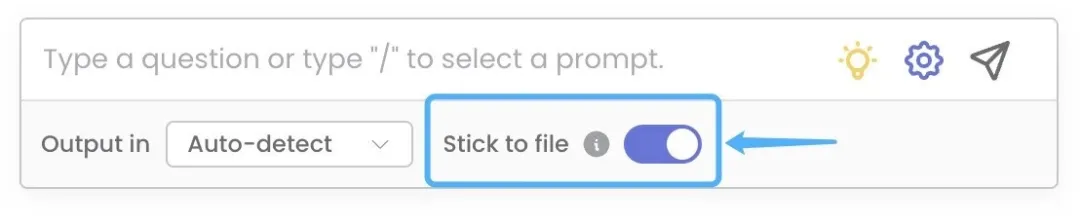
若希望 ChatDOC 不仅严格按原文回答,也能进行一些自由发散,可以先问一个与文档相关的问题,然后进入 Thread,并关闭「Stick to file」按钮。这时 ChatDOC 会记住之前的上下文,以此为基础进行发散,回答依然会与文档本身有关。
ChatDOC 无自身偏好,不会对事物进行价值判断,只会依据文档所给出的信息,总结原文档的观点。
因此,在提问时请避免主观偏好类的问题,直接询问文档中对于某物/某事的具体信息即可。
问题过于宽泛,会导致 ChatDOC 难以检索定位到相关的文档片段。
它不能代替我们思考,定义「哪个候选人合适」「哪个合同有风险」。它只能根据我们给出的标准检索相关内容:比如北大毕业、在大厂工作过;比如付款周期小于 7 天等等。
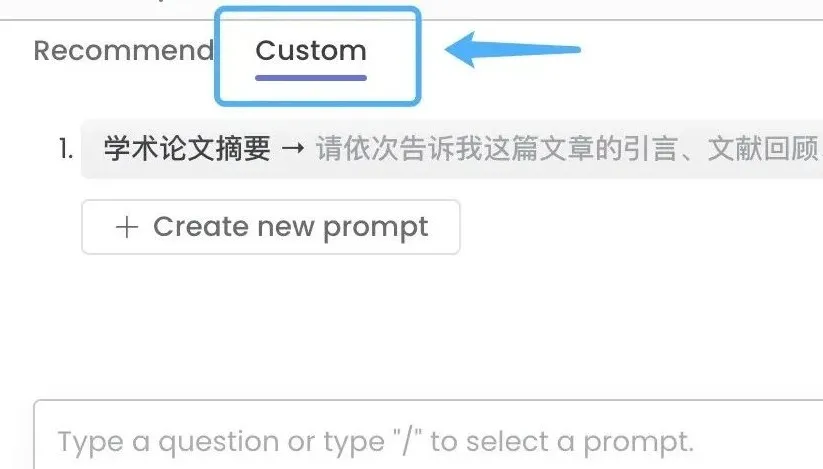
我们还可以将经常使用的标准添加到自定义 Prompt 中,方便日后快速调用。
ChatDOC 近期还会增加用同一问题对多文档逐个提问的功能,敬请期待!
由于大模型每一轮次的输入和输出有 token 限制,ChatDOC 无法进行整个文档的翻译、错别字改写。
但我们可以通过选择片段的方式,让其进行部分文段的翻译、改写。如果翻译到一半,生成的答案中断了,我们可以进入 Thread, 给出指令「继续生成」「继续翻译」,让它在下一次对话中继续回答。
ChatDOC 的原理,是根据问题内容匹配相关文档片段。如果输入「第五章」「第 10 页」,AI 很可能无法理解我们的实际需求是什么。因此,提问时我们应直接提出具体问题。
我们也无需提问「关于 xxx 的信息在第几页」,因为 ChatDOC 会自动给出引用信息来源的所在页数,我们只需点击页码,就能看到原文出处。
AI 需要使用者的正确引导,才能充分发挥力量。祝你学习、探索、使用愉快,Work Faster & Learn Better!